语雀文档导出工具
2024年3月15日 · 1662 字 · 4 分钟 · 前端 Node 文档管理
语雀导出文档工具 (支持单独导出指定知识库)
初衷是之前一直用语雀作为主要文档管理工具(包括团队级文档),但随着量越来越大并且DIY的东西越来越多,再加上有些属于业务机密的逻辑记录,于是准备把语雀上的知识库,使用Node命令一键导出 Markdown 文档,再通过自建文档库的方式使用,这样就不用收到服务商的任何限制了,本篇主要记录工具用法。
计划
在评估了多种导出方案后,我准备选择了使用Node来模拟用户点击事件实现这一功能(因为直接调用API需要超级VIP才行)。Node的跨平台特性和强大的社区库(NPM)使得它成为处理此类任务的理想选择。通过编写一个简单的Node脚本来获取JSON源数据,并捕获返回值并将文档转换保存为Markdown格式(图片不用动,就用语雀的URL源),再搭配比如(Astro\Hugo️️\Docusaurus\Docsify)在本地进行文档管理和内网部署使用。
开源
但想到我肯定不是第一个吃螃蟹的人,那就GitHub搜了搜有几个热门的同质工具,差不多可以满足我的要求,这…, 那必须直接拿来就用了。
第一个是:官方的 exporter 工具 https://github.com/yuque/yuque-exporter
第一个是:普通用户都能直接用的 https://github.com/markyun/yuque-exporter
第二个感觉更符合我的初想,搭配Puppeteer使用起来也很简单,下面简单几步即可。
PS: 在使用这些工具之前,确保你的开发环境中已经安装了 Node.js 和 npm。这是使用 Node 脚本的基础。如果尚未安装,可访问 Node.js 官网 下载并安装。
示例
1. Mac 安装 Chromium (一个开源的浏览器项目,它提供了一个可以用于无头模式(无需图形界面)的浏览器环境)
brew install chromium
2.下载 exporter 工具
- 模拟用户浏览器操作一篇一篇导出 markdown 文档
- 按照知识库目录导出文档
- 支持导出失败重试
- 导出文档中的图片到本地
- 替换文档中的图片链接
git clone https://github.com/markyun/yuque-exporter.git
npm install
3. 运行 node 脚本
# 第一次运行时,使用 USER + PASSWORD 登录 EXPORT_PATH 导出不用写
# USER=xxx PASSWORD=xxx node main.js
USER=xxx PASSWORD=xxx EXPORT_PATH=/path/to/exporter node main.js
# 登录一次后会保存 cookie,之后使用cookie登录
# node main.js
EXPORT_PATH=/path/to/exporter node main.js
4. 常见错误
如果这么简单的话,就不用我写记录了。直接看官方MD文档就行, 需要注意的(我是 M1 芯片 Mac 系统):
一般安装 npm install 这一步就会出错, Puppeteer 依赖的 Chromium 必须需要手动安装。设置跳过 PUPPETEER_SKIP_DOWNLOAD。
出错内容:
puppeteer postinstall$ node install.js
│ ERROR: Failed to set up Chromium r1108766! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to skip download.
│ Error: read ECONNRESET
│ at TLSWrap.onStreamRead (node:internal/stream_base_commons:217:20) {
│ errno: -54,
│ code: 'ECONNRESET',
│ syscall: 'read'
│ }
另外一个错误是: 因为跳过了 chromium 的安装, 需要手动指定 chromium所在路径,也就是 第一步 brew 安装的文件路径.
export CHROMIUM_EXECUTABLE_PATH=/Users/xx/Documents/chromium
// chromium 在mac上默认安装英特尔版本,如果想安装M1版本需要使用下面方式安装
PUPPETEER_EXPERIMENTAL_CHROMIUM_MAC_ARM=1 npm install puppeteer
brew reinstall chromium
// const page = await BrowserPage.getInstance();
const browser = await puppeteer.launch({
headless: true,
executablePath: '/Applications/Chromium.app/Contents/MacOS/Chromium',
});
// true:not show browser
5.运行 node 脚本 成功反馈
node main.js 如果成功后,会显示 如图所示内容就表示下载成功了.
扫描完成后,会下载全部内容
6.支持单独导出指定知识库
如果不想下载全部知识库,可以在这里根据api获取对应知识库的ID,限制。
ps: 因为有的同学,知识库内容太多,可以在 getAllBooks 函数中,拿到 bookData 数据后进行判断,只下载需要的 books 知识库。
// 直接硬编码也可以
if (object.books[i].id ===48016029) {}
完整版
// 调用处
const booksId=882422;
const books = await getAllBooks(page,booksId);
// 可以自己DIY
export async function getAllBooks(page,booksId) {
const books = [];
const response = await page.goto('https://www.yuque.com/api/mine/book_stacks', { waitUntil: 'networkidle0' });
const data = await response.text();
const parser = jsonstream.parse('data.*');
const bookData = await new Promise((resolve) => {
const parsedBooks = [];
parser.on('data', (object) => {
parsedBooks.push(object);
});
parser.on('end', () => {
resolve(parsedBooks);
});
parser.end(data);
});
for (const object of bookData) {
for (let i = 0; i < object.books.length; i++) {
if (booksId && object.books[i].id ===booksId) {
const book = new Book(object.books[i].id, delNonStdChars(object.books[i].name), object.books[i].slug);
console.log("book",book);
book.root = await getBookDetail(page, book);
book.user_url = object.books[i].user.login
books.push(book);
}
}
}
console.log(`Books count is: ${books.length}`);
return books;
}
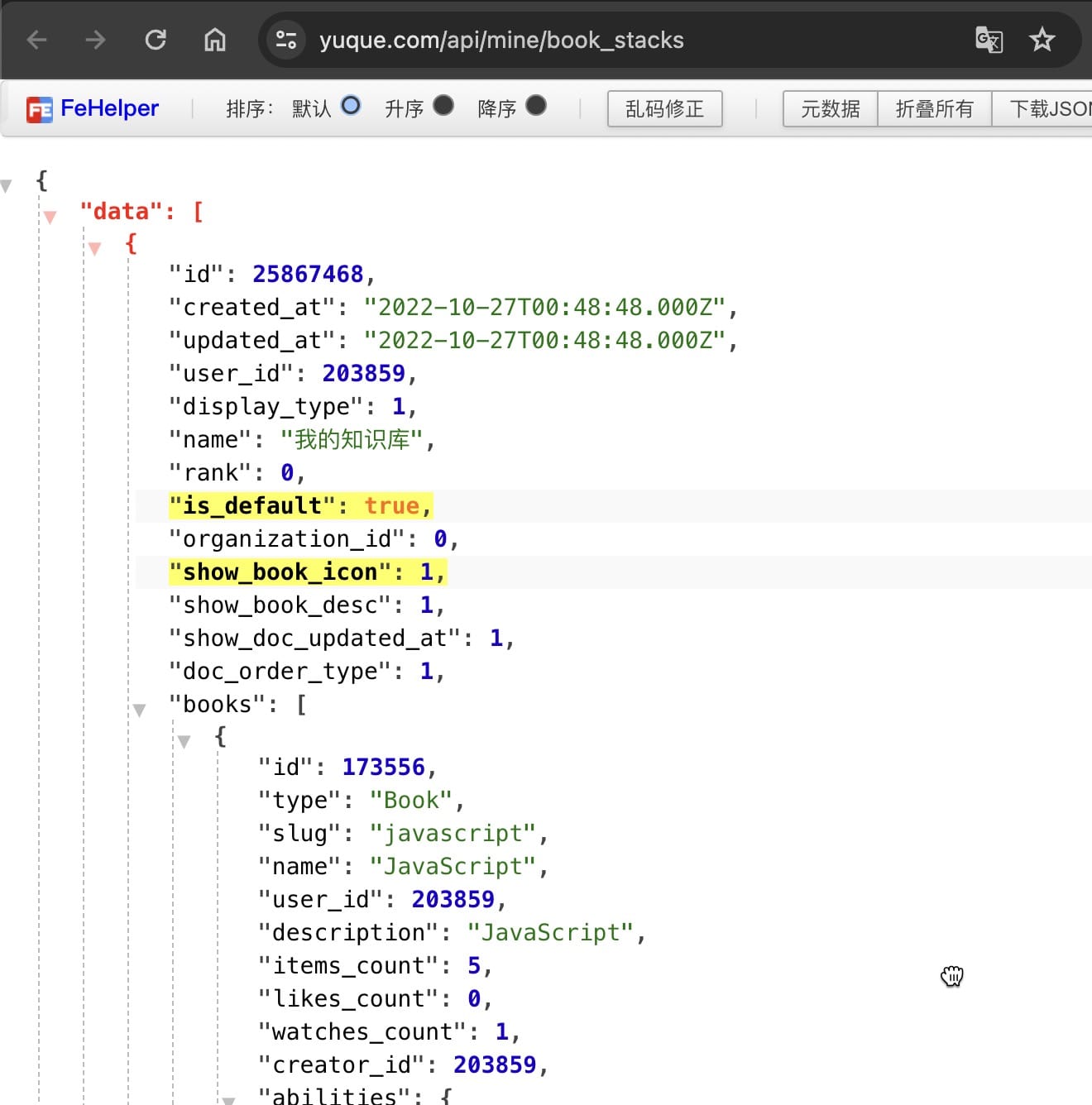
通过 https://www.yuque.com/api/mine/book_stacks 接口获取 全部 bookData 内容,拿到想要的 object.books[i].id。
通过https://www.yuque.com/api/catalog_nodes?book_id=173556 +id 可以得到当前知识库的全部文章列表 getBookDetail 内容。(这样相当于,如果你想下载别人开放的知识库,也是可以DIY的)
下载图片 export-image
// Mac系统 下载图片 python3 export-image.py
// 需要先安装 requests pip3 install requests
语雀文档 导出后的格式处理
url 后面跟上下方的参数,也可以直接获取单篇文档的markdown格式。
/markdown?plain=true&linebreak=false&anchor=false
?view=doc_embed&from=kb&from=kb&outline=1&title=1
替换语雀图片后缀:
这个步骤将会删除保存的图片的多余部分,使图片能够正常显示。这个方法无需运行脚本,只需要使用 Markdown 编辑器进行简单的文本替换操作即可解决问题。
#averageHue=[a-zA-Z0-9\-&=%\.]*
正侧替换为 空
<!-- 同时项目的HTML头,添加下面的信息 -->
["meta", { name: "referrer", content: "no-referrer" }],